Bagging이란 Ensemble의 한 종류로 Booststrap aggregating의 약자이다.
배깅은 분산을 줄이는 알고리즘이며, 의사결정나무는 다른 모형에 비해 상대적으로 분산이 높기 때문에 종종 활용된다.
1. Bagging의 특징
- 단일 모델에 비해 설명하기 쉽다는 구조가 깨짐
- 배깅은 편향이 작고 분산이 높은 모델에 사용하면 효과적
(→ High variance면, 데이터셋에 따라 모델이 심하게 변동한다는 것을 의미)
- Bagging은 variance를 줄여줌, not bias
→ n이 늘어났다고 기대값이 바뀌지 않음. 단, variance는 감소
- 대표적인 Bagging의 알고리즘으로는 Random Forest가 있다.
2. Bagging의 Concept
각 관측값 집합이 가진 분산에 평균을 취하면 최종 분산이 줄어드는 점에서 출발
- Bootstrap을 집계함.
병렬로, 복원추출로! 이것이 point 이다.
1) Bootstrap을 여러 번 반복하고 각각의 Training set을 생성 (각각은 독립)
2) 그 Training set에 Homogeneous weak learner(동일한 모델)들을 서로 병렬적(parallel) & 독립적(independent)으로 학습시킴
3) 그 결과값에 평균을 냄으로써, 분산을 줄이는 기법
- 동일한 모델을 사용하고, 데이터만 분할하여 여러 개 모델을 학습하는 앙상블 기법

3. Algorithm
수식으로 표현하면 아래와 같다.

함수(f)는
예측모형을, B는 학습 데이터셋의 총 개수, b는 각 데이터셋을 의미한다.
일반적으로 학습 데이터셋을 여러 개 얻는 것은 불가능하므로 여기에 부트스트랩을 활용하게 된다.
즉, 다수의 학습 데이터셋 대신 주어진 학습 데이터셋을 여러 번 복원추출(sampling with replacement)하여 활용한다.
이를 다시 수식으로 표현하면 다음과 같다.
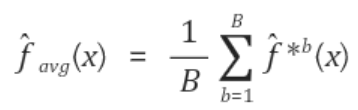
*b는 부트스트랩한 훈련 데이터셋(bootstrapped training data set)을 의미함
모형의 마지막 단계에서 평균을 취하게 되고, 평균을 구할 수 없는 범주형의 경우는 'Voting' 투표를 구하면 된다.
B개의 부트스트랩한 훈련 데이터셋을 만들고 각 *b의 데이터에 의사결정나무를 수립한다.
이 때, 각 의사결정나무는 가지치기 하지 않는데, 이는 각 모형의 분산을 의도적으로 높게 함과 동시에 편향성(bias)을 낮게 만들기 위함이다.
왜냐하면 배깅의 마지막 단계에서 각 모형에 평균을 취하기 때문에 분산이 낮아지기 때문이다.
Q. B의 값은 어떻게 정하는가?
정확도의 측면에서 B는 크면 클 수록 좋다.
B는 과적합(overfitting)과 상관 없는 부트르스랩 횟수이기 때문이다.
(그러나 실제 비즈니스 등에 배깅을 활용하는 경우 B가 클수록 모형 학습에 필요한 시간이 증가한다는 사실에 주의해야 한다.)
4. 결과의 해석
배깅은 여러 나무를 적합(fitting)함으로써 예측력을 높이지만, 반대로 복잡하기 때문에 해석하기 어렵다.
하지만 RSS(Sum of Squared Residuals)나 분류의 경우 Gini index를 활용하여 예측의 측면에서 입력변수의 중요성을 확인할 수 있다.
구체적으로, 각 변수에 대한 나무의 가지로 인해 줄어든 RSS(또는 Gini index) 총 합을 B(부트스트랩한 훈련 데이터셋의 개수)로 나눈다.
이를 입력변수의 중요도(Variable Importance)로 삼아 값이 클 수록 해당 변수가 예측에 중요하다고 해석할 수 있다.
5. Weakness of Bagging
배깅은 feature를 모두 사용하고, row를 Bootstrap을 이용하여 랜덤하게 선택하는 것이다.
Decision Tree를 만든다고 가정해보자.
만약 영향력이 높은, Information Gain이 높은 모델을 사용한다고 했을 때, 특정 Feature만 계속 선택되서 트리가 만들어질 가능성이 있다. 즉, 중요한 칼럼들이 트리의 초기 분기때 모든 표본에 그대로 존재하게 된다. 이렇게 되면 만들어진 대다수의 트리들의 결과가 비슷해진다.
이것이 반복되면 트리간의 상관관계가 발생해서 분산 감소의 효과가 줄어들게 된다.
(배깅의 약점은 IID condition이다. IID 조건을 만족하는 경우 분산은 Var=σ2n이 되지만, IID를 만족하지 못하는 경우, 상관관계가 발생하여 Corr=p이라고 할때, Var=pσ2가 된다.)
→ 그래서 혁신적인 아이디어와 함께 등장하게 된 것이 Random Forest 이다.
[Reference]
https://tkdguq05.github.io/2019/05/05/Ensemble-Model/
blog.hyeongeun.com/21
'통계 톺아보기 > 01. 분류모델' 카테고리의 다른 글
| 02_01_01. 의사결정나무 Decision Tree (0) | 2021.05.26 |
|---|---|
| [02_02_02] Bootstrap (0) | 2020.09.30 |
| [02_02_05] Boosting (AdaBoost) (0) | 2020.08.30 |
| [02_02_04] Boosting (0) | 2020.08.23 |
| [02_02_01] Ensenble (앙상블) 이란? (0) | 2020.08.23 |



