작년에 다시 더듬어 공부하면서 정리한 내용을 포스팅해보려고 한다~ :)
변수의 규칙 또는 조건문을 토대로 나무 구조로 도표화하여 분류와 예측을 수행하는 방법
: 대상이 되는 집단을 몇 개의 소집단으로 구분하는 Segmentation 모델링 기법 (그룹의 특성을 발견하고자 하는 경우)
: Feature Selection에 사용되기도 함 (변수선택)
1) 장점
- 이해와 해석이 쉬움
- 비모수적 모형, 결측값을 효과적으로 다룰 수 있음
- 계산이 빠름
- 교호작용을 고려할 수 있음
- Transformation해도 변화가 없음
- 분포에 대한 가정이 필요 없음
- 비선형적
2) 단점
- 교호작용 지나치게 강조
- 예측 표면이 부드럽지 않음
- 같은 데이터로 다른 Tree들을 만들 수 있음
- 불안정함 (분산이 큼)
- 정확도가 다른 방법보다 낮음
■ Decision Tree의 구성요소


Terminal node(leaf node)에 속하는 데이터 개수를 합하면 root node의 수와 일치함
즉, terminal node간에 교집합이 존재하지 않음
Terminal node(끝마디)의 개수가 root node에서 분리된 집합의 개수가 됨
■ Procedure of decision tree
1) Decision Tree 형성 (Growing Tree)
: CHAID (Kas 1980), CART (Breiman etal, 1984), C45(Quinlan, 1993). 분석의 목적과 자료구조에 따라 적절한 분리기준(split criterion)과 정지규칙(stopping rule)을 지정하여 의사결정나무를 얻는다.
2) 가지치기 (Pruning)
: 분류오류(classification)를 크게 할 위험(risk)이 높거나 부적절한 추론규칙(induction rule)을 가지고 있는 가지(branch)를 제거
3) 타당성 평가
: 이익도표(profit chart)나 위험도표(risk chart)와 같은 모형평가 도구 또는 평가용 데이터(validation data)에 의한 교차타당성(cross validation) 등을 이용하여 의사결정나무를 평가
4) 해석 및 예측
: 의사결정나무를 해석하고 예측 모형을 구축
■ Decision Tree 형성 (Growing Tree)
1. 분류에 가장 중요한 변수를 선택
2. 선택된 변수에 의해 Data 분류
3. 그 다음 중요한 변수를 선택해서 나머지 Data Set을 다시 분류
4. 일정기준*에 만족 될 때까지 계속 과정을 반복하여 Data를 분류하는 방법
*Tree의 Leaf에 해당되는 Data수, Tree의 깊이 등등
1) Split Rules
- 하나의 부모마디로부터 자식마디들이 형성될 때, 입력변수의 선택과 범주의 병합이 이루어지는 기준
→ 목표변수의 분포를 가장 잘 구분해주는 분할법칙을 잘 발견하기 위해 순수도 혹은 불순도에 의하여 평가함
- 부모마디에 비하여 자식마디들에게 순수도가 증가(불순도 감소)하는 정도를 수치화한 것
① Purity (순수도) : 목표변수의 특정 범주에 개체들이 포함되어 있는 경우
→ 1/0이 있으면 자식마디 생성시 한쪽으로 몰리도록 생성
→ 1/0이 반반 섞여 있는 경우가 제일 좋지 않은 경우





Entropy, Gini are more sensitive
To grow the tree : use Entropy or Gini
To prune the tree : use Misclassification rate ( or any other method)



정보 이득 (Information Gain) : 어떤 속성을 택함으로 인해 데이터를 보다 잘 구별할 수 있는 것을 의미. 의사결정 나무에서는 엔트로피와 지니계수가 이 역할을 함
- Information theory : 잘 일어나지 않는 사건의 정보는 자주 발생할 만한 사건보다 정보량이 많다.
- 잘 일어나지 않는 사건 : 확률적으로 낮은 이벤트 ex. 로또에 당첨될 확률
불확실성 정도의 측정이며, 확률적으로 낮으면 information이 증가하고, 확률적으로 높다면 information이 낮아짐
l● Gini Index : 어떤 집합에서 한 항목을 뽑아 무작위로 라벨을 추정할 때, 틀릴 확률을 의미함

l● Entropy
확률분포가 가지는 정보량을 수치로 표현한 것. 확률분포에서 특정한 값이 나올 확률이 높아지고 나머지 값의 확률이 낮아지면 엔트로피가 작아짐. 반대로 여러가지 값이 나올 확률이 비슷한 경우에 높아짐. 확률밀도가 특정값에 몰려있으면 엔트로피가 작고 여러 값에 골고루 퍼져있다면 엔트로피가 큼엔트로피보다 지니 불순도 방식이 불순도 값을 줄이기 위해 더 클래스 확률을 낮추어야 함. 즉 엔트로피 방식이 조금 더 균형잡힌 트리를 만들 가능성이 높음

l 지니 불순도의 장점은 로그 계산이 필요가 없어 구현 성능이 조금 낫다
l 오분류율로 불순도를 측정할 수 있지만 지니지수와 엔트로피와 달리 미분이 불가능하여 자주 쓰이지 않음
2) 가지치기 (Pruning, Post-Pruning)
: Training Set에서 만든 트리를 Validation Data Set에서 가지치기함
재귀적 분기를 통해 계속 분기해 끝마디(Terminal Node)의 순도가 100%인 상태를 Full Tree라 한다. 이런 Full Tree는 과적합(Overfitting)이 될 확률이 높기 때문에 적절한 수준의 terminal node들을 결합해줘야 함
데이터를 버리는 개념이 아닌 분기를 합치는(merge)개념으로 이해해야 함
https://raw.githubusercontent.com/michaeldorner/DecisionTrees/master/01_Seminar%20Paper/seminarpaper.pdf
Using a tight stopping criterion tends to create small and underfitted decision trees. On the other hand, using loose stopping criterion tends to generate large decision trees that are overfitted to the training set. To avoid both extremes, the idea of pruning was developed: A loose stopping criterion is used and after the growing phase, the overfitted tree is cut back into a smaller tree by removing sub-branches that are not contributing to the generalization accuracy.
① Reduced Error Pruning
검증데이터(Validation Set)에 대해 오분류가 증가하는 시점에서 가지치기 수행

Algorithm)
Input : Data Set X, attribute set A, target y
Output : Pruned Decision Tree
ⅰ. X를 training Set Xt와 validation set Xv 로 나눔
ⅱ. Xt에 대해서 속성 A들에 대한 Growing Tree한 T tree 생성
ⅲ. T tree에 Xv 데이터셋 적용하여 각 노드에 대한 error rate 산출
ⅳ, Xv에 대해서 Chiledren node의 error의 합보다 특정 노드의 error rate가 작으면 해당 노드를 terminal node( or leaf node)로 전환
ⅴ. 해당 내용을 반복함
→ 데이터 셋을 Training과 Validation으로 나눠야 해서 데이터 size가 줄어드는 단점이 존재함
② Cost Complexity Function (proposed by Leo Breiman)
Weakest link pruning or error complexity pruning으로 알려짐
위에서 설명한 Reduced Error Pruning처럼 간단하지 않음
Size와 tree의 추정된 error rate를 고려하여 pruning함
(Decision Tree의 전통적인 CART가 이 방법으로 가지치기함)
Cα(T) = R(T) + α|T˜|, α ≥ 0
Cα(T) : Total cost of tree T, Tree that is lower error rate & less terminal node(leaves) is the best.
R(T) : weighted summed error of the leaves(terminal nodes) of tree T
Sum of misclassification error at each leaves ((validation 의 오분류율))
α : penalty for complexity of the tree T˜ (complextity parameter), hyper parameter
T˜ : all leaves in tree T , the number of leaves (terminal node), meaning for complexity of the tree
CCT=ErrT+α*L(T)
CC(T) : 의사결정 나부의 cost function 값. 오류가 적으면서 terminal node수 적은 단순 모델일수록 작은 값
Err(T) : 검증데이터에 대한 오분류율
L(T) : terminal node의 수 (구조 복잡도)
α : 가중치 (보통 0.01~0.1 사이의 값을 사용) hyper parameter

오분류 확률 비교하여 작은 것 선택
③ Error-Based Pruning (c4.5)
※ Reduced error pruning과 Cost-Complexity pruning은 over-pruning 되는 경향이 있으며, 반면에 Error-Based pruning은 under-pruning되는 경향이 있음
결정트리 알고리즘들의 비교 (C4.5 / CART / CHAID)
출처: https://ai-times.tistory.com/177 [ai-times]https://ai-times.tistory.com/177
3) 타당성 평가 (Model Assessment)
: 모형이 우수한지, 다른 모형들 중 어떤 것이 가장 우수한지 비교, 분석
: 모형평가 도구 (이익도표(Gain Chart)나 위험도표(Risk Chart)) 또는 평가용 데이터에 의한 교차타당성 (Cross-Validation)이용해 평가
예측 정확도/평가, 속도와 확장성, 모델 구축 시간 „모델 사용 시간/튼튼함, 노이즈 및 결측값에 영향을 미침/해석 ,이해 및 통찰 모델
Model Accessment 기준
분류정확도 / Gain Chart(이익도표) / Response(반응률) / Lift(향상도) / ROC / ROI
① 분류 정확도
Confussion matrix


- 오분류 확률 (misclassification rate) : 분류 모형이 전체 중 잘못 예측한 수의 비율
(실제0, 예측1 FT)의 수 + (실제1, 예측0 TF)의 수 / 전체
- 정분류 확률 : 분류 모형이 전체 중 올바로 예측한 수의 비율
(실제0, 예측0 FF)의 수 + (실제1, 예측1 TT)의 수 / 전체
- 민감도 (sensitivity) : (실제1, 예측1)의 수 / 실제 1의 수
- 특이도 (specificity) : (실제0, 예측0)의 수 / 실제 0의 수
→ 정오분류 행렬에서 오차율, 정오율만으로 모형 평가 할 수 없다. 모형의 민감도/ 특이도도 함께 고려해야 함
Ex.) Credit Risk 예측 시, 실제 전체 우량 고객 중 우량 고객으로 옳게 예측한 경우보다 실제 전체 불량 고객 중 불량 고객으로 옳게 예측한 경우가 더 중요할 수 있음
Ex.) 암 진단 시, 같은 오류에서도 실제 암이 아닌 경우를 암이라고 잘못 예측하는 것보다 실제 암인 경우를 암이 아니라고 예측하는 것이 더 위함한 경우가 될 수 있음


→ Case2가 Case1보다 손실 비용이 적기 때문에 Model2가 더 우수함
→ 같은 정오율을 같고 있지만 손실 비용면에서 차이가 존재하기 때문에 고려할 필요가 있음
→ 실제 Business상에서 고정된 예산과 같은 제약 조건 하에서 이윤 극대화, sales 목적 달성에 맞는 계획을 설계하고 실행해야 함
② ROC Curve





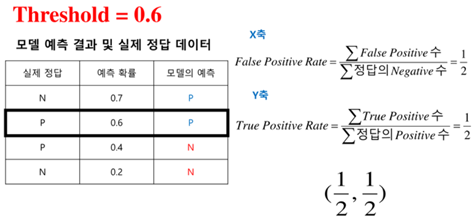




ACU : Area Under the Curve
https://nittaku.tistory.com/297
③ Response chart

④ 이익도표 (Gain Chart)
분류된 관측치가 각 등급별로 얼마나 포함되는지 나타낸 도표


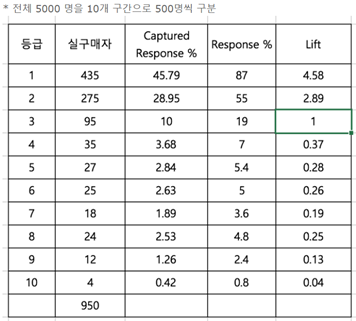
⑤ 향상도 곡선(Lift Chart)
랜덤 모델과 비교하여 해당 모델의 성과가 얼마나 향상되었는지 각 등급별로 파악하는 그래프


'통계 톺아보기 > 01. 분류모델' 카테고리의 다른 글
| [02_02_03] Bagging (0) | 2020.10.04 |
|---|---|
| [02_02_02] Bootstrap (0) | 2020.09.30 |
| [02_02_05] Boosting (AdaBoost) (0) | 2020.08.30 |
| [02_02_04] Boosting (0) | 2020.08.23 |
| [02_02_01] Ensenble (앙상블) 이란? (0) | 2020.08.23 |



