통계 톺아보기/01. 분류모델
[02_02_01] Ensenble (앙상블) 이란?
늉이늉이
2020. 8. 23. 15:50
1 . Ensenble 개념
- weak learner 들을 잘 조합해서 strong learner로 만드는 것
- 성능이 그리 좋지 않은 모델들을 모아서 성능이 좋은 모델 하나를 만드는 것
- 여러 분류 모델이 만든 결과를 집계하여 예측 혹은 분류하는 방법
2. General Idea

Step1: Training Data를 Multiple Data Set으로 분류
Step2: 각각의 Multiple Data Set에서 분류모델 생성
Step3: 각각 생성된 분류모델을 결합
3. Ensenble 모델
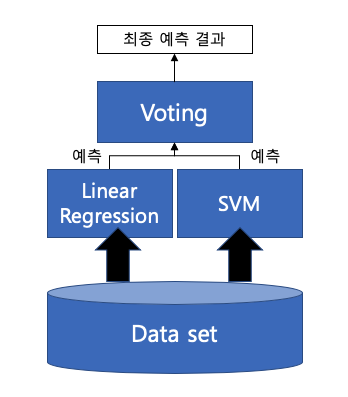
1) Voting
- 여러 개의 분류기가 투표를 통해 최종 예측 결과를 투표를 통해 결과 도출
- 서로 다른 알고리즘을 여러개 결합하여 사용
- 하드 보팅(Hard Voting) , 소프트 보팅(Soft Voting) 이 있음
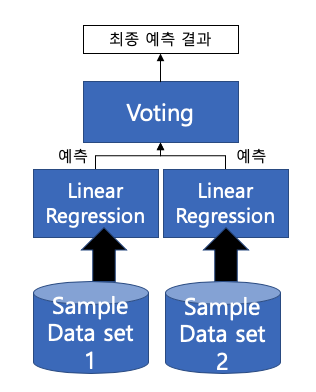
2) Bagging
- Bootstrap Aggregating (샘플을 다양하게 중복 생성)
- 데이터 샘플링을 통해 모델을 학습시키고 결과를 집계하는 방법
- 같은 유형의 알고리즘을 사용
- Over-fitting 방지
- 대표적인 Bagging : Random Forest
3) Boosting
- 여러 개의 분류 모델이 순차적으로 학습 수행
- 이전 분류기에서 예측이 틀린 데이터에 대해 잘 분류 되도록 가중치를 부여하여 다음 분류기에 적용하는 방식으로 학습과 예측을 진행 (이전 오차를 보완하며 가중치 부여)
- 계속하여 분류기에 가중치를 부스팅하며 진행함
- 대표적인 Boosting : XGBoost, LightGBM
- 배깅에 비해 성능이 좋지만, 느리고 Over-fitting 발생 가능성이 존재함
4) Stacking
- 여러 모델을 기반으로 meta 모델
[참고]
1) http://www.dinnopartners.com/__trashed-4/