일반적으로 Over-fitting 문제를 해결하기 위한 방법으로 3가지 방법을 사용합니다.
1. 기존보다 더 많은 데이터를 이용하기
2. Feature 개수를 줄이기
3. Cross-Validation
4. Regularization(정규화)
언급한 4가지 중에서 Regularization 을 이해하기 위해, Norm을 먼저 이해하고자 합니다.
Norm
Norm은 벡터의 길이 혹은 크기를 측정하는 방법(함수) 이다. 두 벡터 사이의 거리를 측정하는 방법이기도 하다.

수식에서 p는 Norm의 차수를 의미한다. p=1 이면, L1 Norm 이고, p=2 이면, L2 Norm을 의미한다.
n은 벡터의 원소 수이다.
1. L1 Norm
p=1 인 Norm이며, L1 Norm을 Taxicab Norm 혹은 맨허튼 노름(Manhattan norm) 이라고도 합니다. L1 norm은 벡터의 요소에 대한 절댓값의 합입니다. 원점과의 거리를 아래와 같이 표현할 수 있다.


예를 들어 벡터 p =(3, 1, -3), q = (5, 0, 7) 이라면 p, q의 L1 Norm 은 |3-5| + |1-0| + |-3 -7| = 2 + 1 + 10 = 13 이 된다.
L1 Norm을 그림으로 살펴보자.

이렇게 표현할 수 있으며, 아래 그림과 같이 마름모의 형태로 나타난다.

2. L2 Norm
p=2 인 Norm이며, L2 Norm을 n 차원 좌표평면(유클리드 공간)에서의 벡터의 크기를 계산하기 때문에 유클리드 노름(Euclidean norm)이라고도 합니다. 아래 수식은 원점으로부터 직선의 거리라 할 수 있다.


이렇게 표현할 수 있으며, 아래 그림과 같이 원형태의 Unit Circle로 나타난다.

3. L1 Norm과 L2 Norm 비교
검정 두 점 사이의 거리를 살펴보고자 한다.
L2의 경우는 초록선으로만 표현될 수 있지만, L1의 경우 빨강, 파랑, 노란색 선으로 표현될 수 있다.
L1 Norm은 여러가지 Path를 가지지만, L2 Norm은 Unique Shortest path만 가짐

좋은 모델이란? 1)현재 데이터 training data를 잘 설명하는 모델
2) 미래 데이터 test data 에 대한 예측 성능이 좋은 모델
1) 에 대해서는 Training Error를 minimize하는 모델

Expected MSE는 아래와 같이 유도된다.

bias, variance가 나오는데, bias와 variance를 줄여서 Expected MSE를 줄이는 것이 좋다.
둘의 관계가 trade-off 관계이므로 둘 다 줄이지 못한다면, 둘 중에 하나라도 작은 것이 좋게 된다.
Bias가 증가하더라도 variance가 감소폭이 크면 expected MSE가 줄어들게 된다.
우리가 알고 있는 Least squares estimation method (최소제곱법) : 평균제곱오차 MSE를 최소화 하는 회귀계수를 계산
실제 값과 예측 값의 차이를 가장 작게하는 회귀계수를 추정
알려져있지 않은 회귀계수를 점추정량을 구하기 위해 최소제곱법을 사용하는 것이다.
아래와 같이 구한 회귀계수들은 unbiased estimator라는 좋은 성질을 갖고 있다.
분산이 가장 작은 점추정량이기 때문에, 최소제곱법으로부터 구한 점추정량은 좋은 성질을 가지고 있고, 이를 BLUE라 한다.

bias가 없는 unbiased 중에서는 가장 분산이 작지만, bias estimator지만 분산이 더 작은 회귀계수를 추정할 수 있지 않을까? 하는 의문 발생
빠밤!!
Subset Selection 이라는 방법론을 먼저 설명하면,
전체 p개의 설명변수(x) 중 일부 k만을 이용하여 회귀계수 beta를 추정하는 방법이다.
전체 변수 중 일부만 선택함에 따라 bias가 증가할 수 있지만 variance가 감소
정규화란 ?
1,2,3 모두 선형모델
1:직선, 2: 2차식, 3: 4차식인데, 1,2,3중 어떤게 가장 잘 설명하고 적합할까?
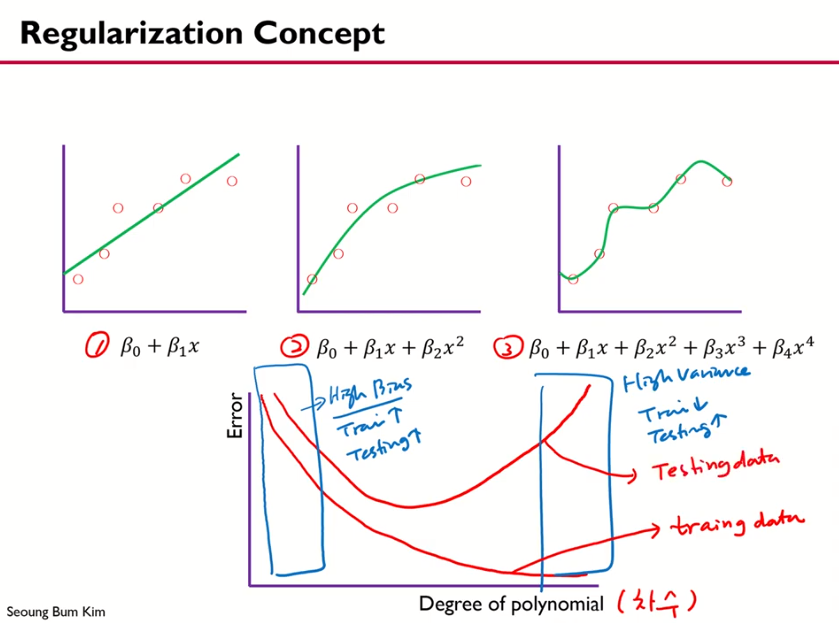
x축은 차수,
차수가 작을수록 train, test에 대한 error가 둘 다 큼. 이 경우는 bias가 큰 것을 의미 (1번 model)
두번째 박스의 경우는 train은 작지만 test는 매우 error가 큼. high variance로 3번 model(4차수) 의미
예제에선 2번이 더 낫다고 볼 수 있다.
결국, train 관점에서 아래 1번에서는 train에서는 잘 fitting하지만 test에 대해서는 잘 예측하지 못하게 된다.
따라서, 1번에서 2번으로 적합하는 model을 찾고자 한다.

두 개의 그래프 아래 수식을 보면, β3, β4 앞에
수식은 최소제곱추정법 형태이다. β3, β4 에 5000을 곱해져 있고, 이 전체 식을 최소화하려면 어떻게 해야할까?
전체가 최소화 되려면 β3, β4가 0에 가까워지면 된다.
이런식으로 5000을 곱해주는 제약을 걸어준 것이고 panalty를 준 것이다.
regularization은 결국 계수에 panalty를 줌으로써 modeling에 변화를 주는 것이다.
제약을 주었다! 의 의미로 생각하면 좋다.

lambda가 제약조건이 됨.
(1)은 mse를 최소화하는, 현재 갖고있는 데이터를 최소화 하겠다의 의미인데, (2)를 추가함으로써 예측데이터에 대한 정확도도 고려해보자. 데이터에 제약을 줘서.
λ : regularization parameter that controls the trade-off between (1) and (2)
hyper parameter
λ값이 크면 추정되는 계수값이 0에 가까워지게 되고, under-fitting이 됨
λ 값이 작으면, 제약의 효과가 작아지게 되고 Over-fitting이 됨

최소제곱법과 regularization은 beta에 대한 제약조건 유무에 따른 차이이다.
최소제곱법의 경우는 beta에 대한 제약이 없고, beta가 무슨 값이든 mse를 최소화 하는 bias 관점의 unbias 목적
regularized 는 mse도 최소화 하지만 beta에 일정 제약조건을 주고 variance를 줄이겠다.


t와 λ의 역할은 같다.


판별식에 넣어보면, 타원의 모양임이 확인 된다.

제약조건을 만족하는 beta를 찾으면, 최소제곱추정량보다 값이 작아지게 된다.
Regularization => Shirinkage

t가 커지면 제약을 주지 않은 것과 같은 효과

ridge => biased estimator, 예측면에서 좋다. variance가 더 작기 때문에

bias- variance trade-off에 의해 모델이 복잡할수록 variance가 커지니
regularization을 통해서 모델의 복잡성을 감소시켜 모델의 variance를 감소시키게 된다.
[Reference]
www.youtube.com/watch?v=pJCcGK5omhE